Amintiți-vă, atunci când explorați pentru prima dată unele date, primele și cele mai de bază întrebări pe care trebuie să le puneți sunt:
- Datele sunt univariate sau bivariate (sau multivariate)? (1)
2. Sunt categorice sau numerice? (2)
Răspunsurile la aceste întrebări determină ce fel de statistică este relevantă și ce fel de reprezentare grafică este adecvată.
Exemplu: să presupunem că explorăm un set de date de lucrări literare extraordinare:
books.iloc
▌ gen an limba cuvinte capitole
▌nume
▌Jane Eyre F 1847 Engleză 183858 38
▌Brothers Karamazov M 1879 Rusă 364153 92
▌Anna Karenina M 1877 Rusă 349736 219
▌The Inferno M 1320 Italiană 45750 34
▌Huck Finn M 1884 Engleză 109571 43
Pentru fiecare carte, avem sexul autorului, anul și limba în care a fost scrisă și numărul total de cuvinte și capitole pe care le conține. În mod clar, genul și limba sunt variabile categorice, în timp ce anul, cuvintele și caracterele sunt numerice.
Date univariate: categorice
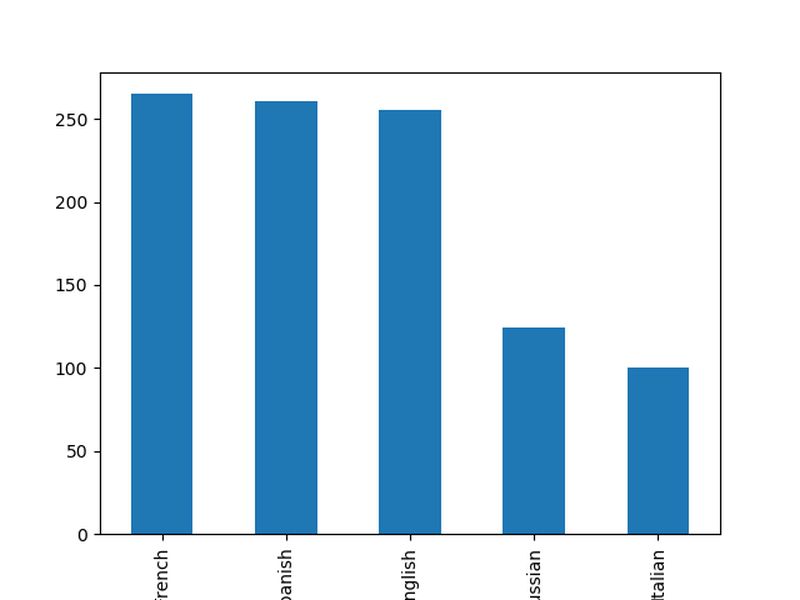
Când ne uităm la o singură variabilă, care este de natură categorică, analiza adecvată este tabelul de contingență unidimensional, care arată numărul diferitelor valori. Să creăm un tabel de contingență pentru limbile cărților, folosind funcția .value_counts() de la Pandas:
books.value_counts()
▌Franceză 299
▌Engleză 247
▌Spaniolă 217
▌Rusă 150
▌Italiană 92
▌Nume: lang, dtype: int64
Cel mai potrivită reprezentare grafică este o diagramă cu bare cu aceste numere, pe care o puteți crea prin simpla alipire a .plot(kind="bar") la sfârșit:
books.value_counts().plot(kind="bar")
Date univariate: numerice
Când singura variabilă de interes este numerică, ca și coloana cuvintelor, statisticile adecvate sunt media, abaterea standard și diferitele statistici cuantile (minimul, cuantila .25, mediana, cuantila .75, și maximul):
books.mean()
books.std()
books.quantile()
▌436739.737
▌232384.719
▌0.00 5443.0
▌0.25 241492.0
▌0.50 462552.0
▌0.75 637765.0
▌1.00 805341.0
Traducere: în medie, cărțile din setul nostru de date au fiecare aproximativ 436.739 de cuvinte și, dacă sunt distribuite în mod normal (neverificat încă), aproximativ |2/3 dintre ele sunt în intervalul 436.739 ± 232.384 (sau între 204355 și 669123 cuvinte). Cea mai scurtă carte are 5443 de cuvinte, cea mai lungă 805.341, iar jumătate din cărțile din setul de date au 462.552 sau mai puțin. Un sfert dintre cărți au mai puțin de 241.492 de cuvinte, iar trei sferturi au mai puțin de 637.765.
Cea mai bună reprezentare grafică în acest caz este histograma:
books.plot(kind="hist",bins=30)
care arată întreaga „întindere” a repartizării valorilor. Nu uitați să experimentați cu numărul de bin, deoarece puteți obține imagini foarte diferite despre modul în care sunt distribuite datele, în funcție de dimensiunea bin (mai multe despre asta în capitolul 4).
Note:
(1) Datele „univariate” înseamnă că vă uitați la o singură variabilă, chiar dacă există multe observații ale acelei variabile. Scorurile SAT ale unei mulțime de oameni cuprind un set de date univariate, la fel ca o mulțime de afilieri politice, salarii sau majorări declarate. Datele „bivariate” conțin două informații pentru fiecare observație: dacă am date despre atât scorul SAT, cât și GPA la facultate pentru fiecare dintre o mulțime de studenți, acesta este un set de date bivariat. Un alt exemplu: un set de date cu atât sexul, cât și cu salariul pentru fiecare dintre o mulțime de adulți.
(2) Amintiți-vă că o variabilă „categorică” este calitativă, de obicei aleasă dintr-un set de valori posibile. Sexul, afilierea politică și declarația majoră sunt toate exemple. Variabilele „numerice” sunt numere: salariu, GPA, scor SAT. Variabilele numerice pot fi rafinate în continuare prin scara lor de măsură (ordinal, interval, raport), deși adesea acest lucru nu afectează prea mult tipul adecvat de statistici și diagrame exploratorii.
Sursa: Stephen Davies, The Crystal Ball – Instruction Manual, Vol. 2: Introduction to Data Science, v. 1.1. Copyright © 2020 Stephen Davies. Licența CC BY-SA 4.0. Traducere și adaptare: Nicolae Sfetcu. © 2021 MultiMedia Publishing, Introducere în Știința Datelor, Volumul 2
https://www.telework.ro/ro/stiinta-datelor-date-univariate-categorice-si-numerice/
No comments:
Post a Comment